How We Built Multimodal RAG for Audio and Video


Retrieval-Augmented Generation (RAG) has been revolutionizing how we interact with information, but it has largely lived in a world of text. Documents, articles, and code have become searchable and conversational. But what about the vast, unstructured universe of information locked away in audio and video files?
At Ragie, we provide a robust, scalable enterprise grade RAG-as-a-service platform. Last month we launched full, native support for audio and video with Ragie’s RAG platform.
This isn't just about bolting on a transcription service. We’ve re-architected core parts of our pipeline to handle the unique challenges of multimodal data. In this deep dive, we'll walk you through the entire technical journey: how we process, index, and retrieve from audio and video, the critical design choices we made, and how you can leverage these new capabilities in your own applications.
The Ragie Multimodal Processing Pipeline
Every audio and video file uploaded to Ragie goes through a sophisticated, multi-stage pipeline designed for quality, speed, and search relevance.
Here’s a high-level look at the journey of a media file:

Let's break down each step.
1. Preprocessing: Setting the Standard
The first step is normalization. Media files come in countless formats and codecs. To ensure consistency for downstream tasks, we standardize everything.
- Audio: All audio files, whether standalone or extracted from video, are converted to a standardized MP3 format.
- Video: We normalize the video stream to a web-streaming-friendly MP4 container. Critically, we provision GPU resources and use a CUDA-accelerated build of ffmpeg to handle this transcoding as quickly as possible.
2. Data Extraction and Refinement: Understanding the Content
Once normalized, we extract the core information from the medial files:
- For Audio: We generate a highly accurate transcript.
- For Video: We process two streams simultaneously:
- The audio track is sent for transcription.
- The video stream is broken into smaller clips, and each clip is individually described by a Vision LLM to capture the visual narrative.
3. Chunking: Creating Searchable Units
Raw transcripts and descriptions are too large for effective retrieval. We break them down into semantically meaningful chunks.
- Audio Chunks: 1-minute long, non-overlapping segments of the transcript.
- Video Chunks: 15-second long, non-overlapping segments. Each video chunk is a rich object containing both the audio transcript and the visual description for that specific time range.
Most importantly, every chunk is enriched with metadata:
- Timestamps: The start and end time in the original media.
- Source Links: Links to directly stream or download the specific audio/video segment corresponding to the chunk. This is crucial for attribution, allowing downloading of the raw media at the specific time frame that was relevant to send to LLMs for generation or for front-end applications to play back the exact source.
4. Indexing & Summarization
Finally, the processed data is indexed for retrieval and used to generate summaries. All text, audio, and video chunks are fed into our multiple index system (semantic, keyword and summary), making them searchable through a single query. We’ll cover summaries in more detail later.
Deep Dive: Audio Transcription at Scale
For audio, transcription quality and speed are paramount. After extensive testing, we built our audio pipeline around faster-whisper with the large-v3-turbo model.
Here’s why:
- Performance: faster-whisper leverages CTranslate2, a fast inference engine for Transformer models. This makes it 4x faster than the vanilla OpenAI Whisper implementation at the same accuracy level. We run it with float16 precision for an additional speed boost.
- Accuracy: The large-v3-turbo model is an optimized version of Whisper's largest model, offering state-of-the-art accuracy with minimal performance degradation compared to the non-turbo version.
- Features: It provides robust multilingual support and, critically for attribution, precise word-level timestamps.
Deep Dive: The Quest for the Best Video Indexing Approach
Video is more complex than audio because it contains two distinct streams of information: audio and visual. The core question we faced was: What is the best way to represent video content in a searchable format?
We explored two state-of-the-art approaches.
Approach 1: Native Multimodal Embeddings
This approach uses a model like Vertex AI's Multimodal Embedding model to generate a single vector embedding that represents the video content.
- How it Works: The model takes a video clip as input and outputs a dense vector. This vector captures visual information like objects, scenes, and even on-screen text. These vectors are then stored in a vector database.
- The Pros: It allows for "any-to-any" search in a single vector space (e.g., search video with an image).
- The Cons:
- No Voice: It does not capture the audio/speech information.
- Cost & Latency: Our tests showed it was 6x more expensive and 2x slower than the alternative.
- Text Limitation: The model had a maximum text input of 32 tokens, making it impractical for embedding the text content in a production system. We currently process multi thousand page documents. We would have needed a separate embedding model for text anyway, defeating the purpose of a unified system.
Approach 2: Vision LLM Descriptions (Our Chosen Method)
This approach uses a powerful Vision LLM (we use Google's Gemini models) to act as a "translator" from the visual domain to the text domain.
- How it Works: We feed video clips to the Vision LLM and prompt it to generate a detailed text description. This description captures scene details, actions, objects, brands, and reads on-screen text (OCR). This resulting text is then embedded using our standard text embedding models.
A critical parameter in this approach is the duration of the video clips. We faced a trade-off: longer chunks provide more context but risk information loss, as LLMs can struggle to retain details over longer video inputs. Shorter chunks produce more information-dense descriptions, but can become noisy or miss the full context of a scene if they are too short. To find the sweet spot, we experimented with chunk durations of 15s, 30s, and 1 minute. Our testing revealed that 15-second chunks provided the best balance. They were long enough to capture complete, meaningful actions while being short enough for the Vision LLM to generate highly detailed descriptions, leading to the best retrieval performance across our test data and queries.
- The Pros:
- Rich Detail: The generated descriptions are incredibly detailed and nuanced.
- Superior Performance: When embedded, these rich text descriptions performed as well as, and often better than, the native multimodal embeddings in our retrieval tests.
- Speed & Cost: This method proved to be 2x faster and 6x cheaper.
- Unified Search: It allows us to index video-derived text in the exact same vector and keyword indexes as our other text data. This enables seamless, cross-modal search in a single query while preserving all of Ragie's advanced features like hierarchical search and reranking.
- Scalability: Throughput and rate limits were much more favorable for production use cases.
The Verdict: The Vision LLM description approach was the clear winner. It provides higher quality results at a fraction of the cost and speed, and elegantly integrates video into our existing, battle-tested RAG architecture.
Extending Summaries to Audio and Video
A core feature of Ragie is document-level summaries. We extended this to our new modalities.
- Audio Summaries: This was straightforward. We take the full transcript generated during the extraction phase and use a text LLM to create a concise summary.
- Video Summaries: This was more challenging. Our first attempt was to join the text descriptions of all the 15-second chunks and summarize that. The result was disjointed and lacked cohesion. So, we adopted a more sophisticated (and expensive) approach that mirrors our indexing decision. We pass the entire, full-length video to a Vision LLM in one go and ask for a cohesive summary. The results are vastly superior—concise, coherent, and accurately capturing the video's overall narrative. We believe the quality gain is well worth the additional cost.
Media Streaming
We spent a lot of time considering how AI applications would need to use source media that Ragie ingests and indexes. We discovered two primary use case categories: user facing front-ends that will stream the media from the relevant timestamp and workflows that will themselves use the media for a subsequent LLM generation. We designed a system to support both these use cases through straightforward APIs.
Ragie retrievals return a set of ScoredChunks that were most relevant for a query. If a chunk in that set originated from a media file it will include links with that chunk like “self_video_stream” and “self_video_download”. These links are similar in that they will both provide a segment of the video beginning at the point in the video where the chunk was derived. They differ in that the stream link will continue playing past the chunk while the download link ends where the chunk ends. Download is largely intended for cases where the media will be provided to an LLM for further processing.
Media can also be streamed for the entire document using the document contents endpoint and sending the appropriate media_type parameter. Applications can use this approach to add features like highlighting the seek bar at the points where the query matched the source media. This can also be combined with word level timestamps for granular seeking to the most relevant clips in the media.
In order to support all these use cases we go through several steps to normalize the media for AI processing and streaming. When we receive a media file we take the first few megabytes, just enough for ffprobe to discover the video codec, pixel-format and whether an audio track exists. From that probe the normalizer decides whether it can use the more performant NVIDIA NVDEC/NVENC path or it needs to fallback to a plain CPU path. These operations stream from and to storage buckets minimizing memory footprint.
The encoder targets a single optimized general purpose profile: 720 p, 30 fps, one-second GOP, AAC audio at 96 kb/s, and a bitrate that tops out near 5 Mb/s. Those choices are deliberate: 720 p is still the sweet spot for mobile devices, constant frame-rate material plays nicely with HTML5 players, and a one-second key-frame cadence allows fast seeking and clean HLS/DASH segmentation [https://en.wikipedia.org/wiki/Dynamic_Adaptive_Streaming_over_HTTP]. If the original upload contained audio, the pipeline also spins off a lightweight MP3 so listeners can stream or download without pulling video data.
For those curious, our ffmpeg flags for the final MP4 include +faststart +frag_keyframe +dash flags. These options push the moov box to the head of the file and emit media in key-frame-aligned chunks, so the first byte range already forms a valid initialization segment. In practice that means media is streamable from any arbitrary second. The net result is a resilient, GPU-accelerated pipeline that turns arbitrary uploads into low-latency, cross-platform media ready for both end user streaming and LLM consumption.
New Features to Power Your Multimodal Applications
This underlying pipeline unlocks a suite of powerful, developer-ready features:
- Multimodal Indexing and Retrieval: Combine semantic and keyword search across text, audio, and video content simultaneously. Ragie's full suite of features—hybrid search, reranking, recency bias—now works seamlessly across all modalities.
- Visual Search for Videos: Go beyond transcripts. Search for visual elements like "a person wearing a hard hat in a factory" or "who were the main sponsors of super bowl 2025"
- Full Audio and Video Transcriptions: Enable full-text search and analysis of spoken content from podcasts, meetings, customer calls, and more.
- Source Attribution with Chunks: Confidently validate LLM answers. Every retrieved chunk links directly back to the precise audio or video segment it came from, with APIs to embed, stream, or download the clip.
- Application Ready: We're developers, and we build for developers. New APIs and SDKs for multimodal support, comprehensive guides, and integrated audio/video capabilities into Base Chat, our open-source conversational AI app.
Use Cases Unlocked by Multimodal RAG
The ability to search and reason over audio and video opens up a world of possibilities:
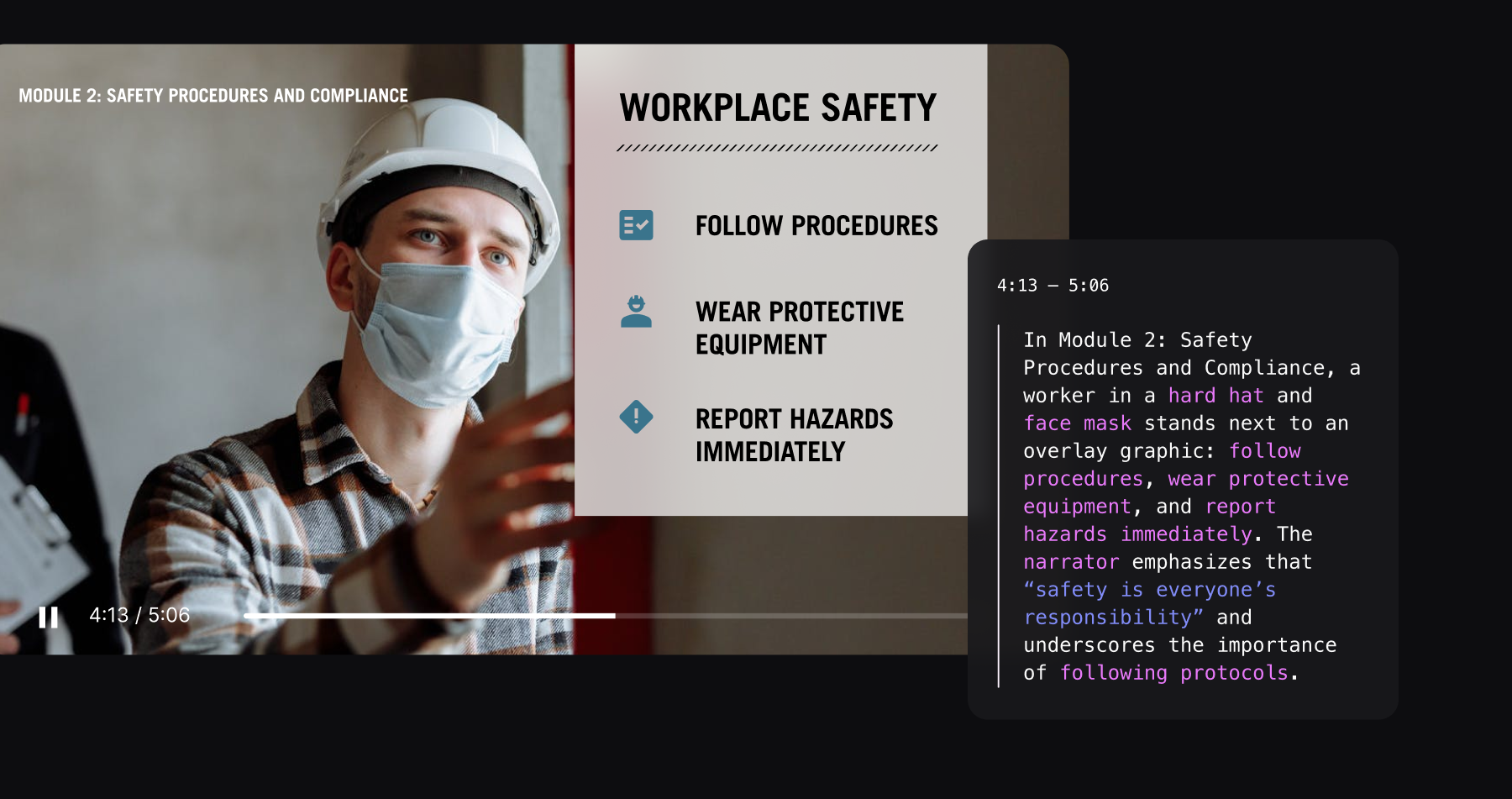
- Corporate Training & E-learning: Make entire libraries of video training modules fully searchable. Employees can ask, "Show me the part of the safety training where they discuss handling hazardous materials," and get the exact video clip.
- Media & Entertainment: Analysts and producers can instantly find relevant segments across hours of interviews or footage. Find every instance a specific person appears on screen or a particular topic is discussed.
- Healthcare & Medical Research: Analyze video recordings of medical procedures or doctor-patient conversations to identify key moments or find visual markers (like medical scans) mentioned in context.
- Legal & Compliance: Search through hours of video depositions or audio recordings of legal hearings for specific phrases, people, or evidence presented.
- Customer Support: Empower support teams to find helpful moments, FAQs, or visual demonstrations from a library of past video calls to resolve issues faster.
Get Started Today
We are incredibly excited to see what you will build. By treating audio and video as first-class citizens in the RAG ecosystem, we are unlocking decades of valuable information that was previously inaccessible.
Dive into our updated documentation and start building your first multimodal application today.