Indexing Enterprise Documents: A Developer's Guide to Integrating SharePoint for RAG


Your company's most valuable intelligence isn't in a clean, structured database. It's buried in thousands of PDFs, Word documents, and presentations stored in document management platforms like Microsoft SharePoint. As a developer, you might be tasked with building an AI application that can reason with this knowledge. But here's the real challenge: How do you create a secure, scalable pipeline capable of ingesting and indexing this messy, unstructured data? It's a difficult process, involving everything from parsing different file formats to handling enterprise-grade permissions.
This is where retrieval-augmented generation (RAG) comes in. RAG is a technique that helps large language models (LLMs) give better answers by grounding them in specific, verifiable information from your documents. The hardest part of RAG is getting the retrieval step right and accurately fetching relevant information from their knowledge base.
In this tutorial, you'll learn how to integrate SharePoint directly into a RAG system using Ragie to securely bring in your documents and start building apps that use your company's knowledge.
Understanding the Enterprise RAG Challenge
At its core, a RAG system enhances an LLM's response by first retrieving relevant information from an external knowledge base and then using it to answer questions more reliably. The following are the three key components of a RAG system:
- The knowledge base: A repository of information. In an enterprise context, this often consists of an extensive collection of unstructured documents in systems like SharePoint.
- The retriever: An information retrieval system responsible for searching the knowledge base. It takes a user's query and finds the most relevant passages of text using techniques like semantic search (which understands meaning, not just keywords) and reranking (which uses AI models to improve the initial search results). This ensures the most relevant information gets passed to the generator.
- The generator: An LLM that receives the original query and the retrieved information and then synthesizes them to produce a coherent, context-aware answer.
While RAG seems to be a simple concept, implementing it in an enterprise setting presents distinct challenges. Knowledge bases contain millions of unstructured documents—PDFs, emails, presentations, and databases—distributed across departments that don't share information systems. On top of that, navigating permission hierarchies where different users access different content while ensuring sensitive data remains protected becomes incredibly difficult at scale.
SharePoint is one of the most widely used document management systems in Microsoft-based organizations. It hosts critical internal resources such as HR policies, product documentation, and research reports. Automating ingestion from SharePoint ensures that your knowledge base stays current without constant engineering intervention. It allows you to connect and manage your own data securely, reduce the manual burden of maintaining document pipelines, and retain control over access, monitoring, and costs.
Connecting SharePoint to Ragie
Ragie a managed RAG-as-a-service platform that handles the complex backend infrastructure required for production-grade RAG systems. It uses connectors to pull in data from sources like SharePoint and then automatically parses, chunks, and indexes your documents for easy retrieval.
In this tutorial, you'll connect a SharePoint document library to Ragie for question answering. The tutorial uses a folder of NVIDIA's quarterly financial reports as an example (you can download it here), but you can follow the same steps with any documents, such as HR policies, technical docs, research papers, or other content.
Configure the SharePoint Connection in Ragie
First, you need to create a free account on the Ragie platform. Once you're logged in, navigate to the Connections section to set up your SharePoint integration.
To create a new connection, click on New Connection in the top-right corner and select SharePoint from the list of available data sources.
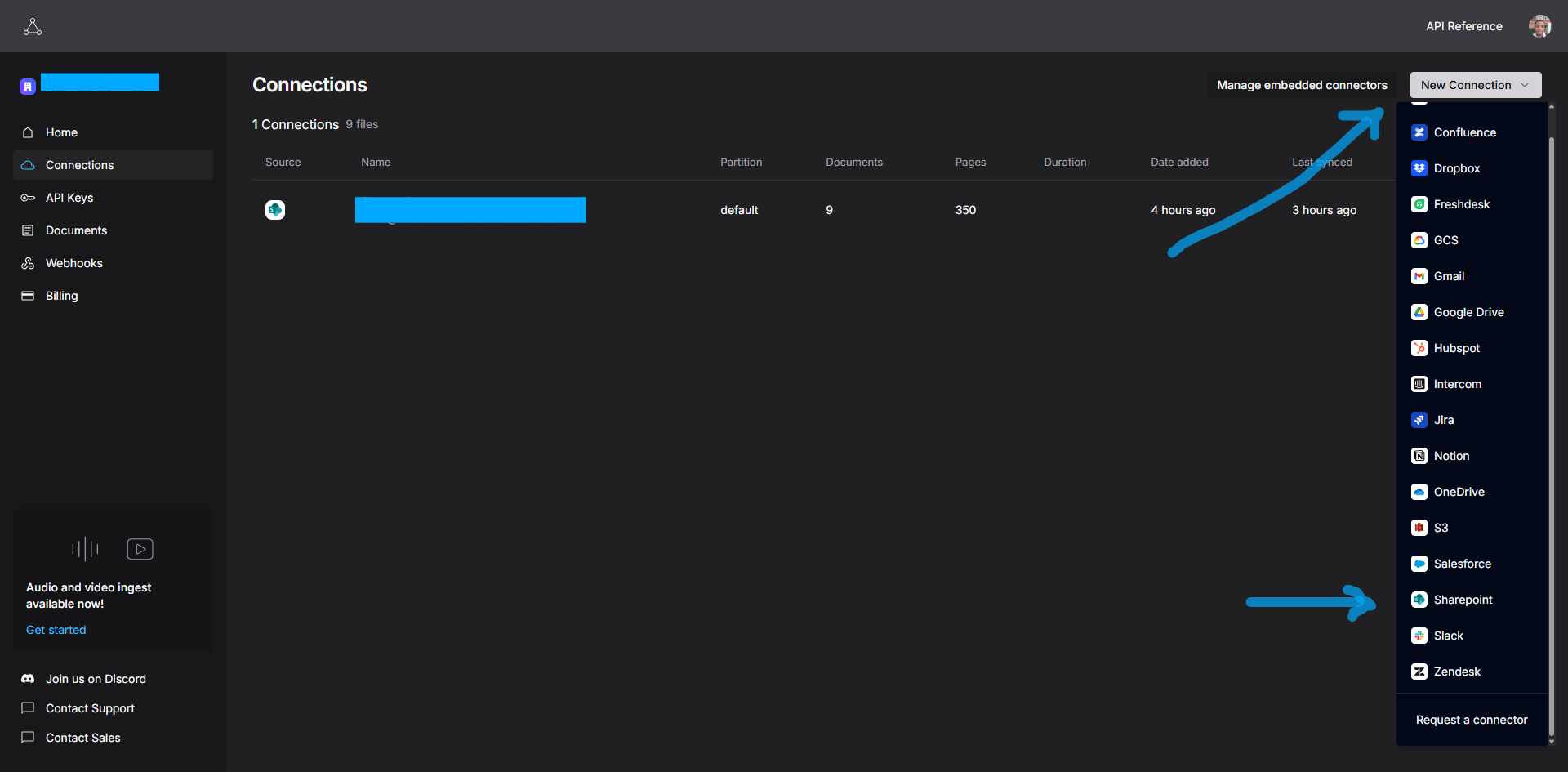
To authorize access, you will be prompted to authenticate with your Microsoft account. This process uses the OAuth 2.0 authorization framework to grant Ragie secure, token-based permissions to access your SharePoint files without exposing your credentials.
To configure your connection settings, you need to define exactly what data to sync and how:
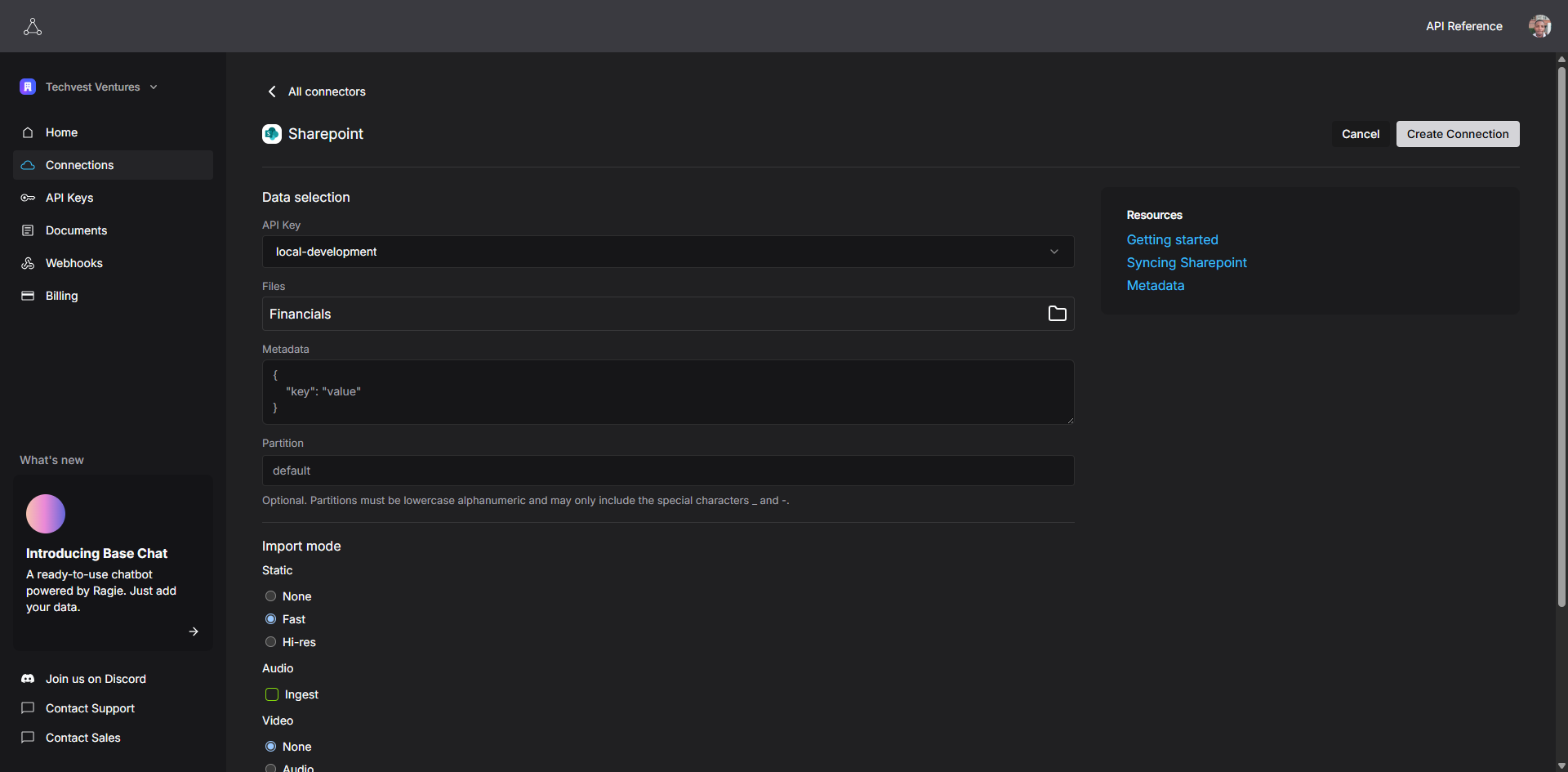
- Select files/folders to sync: You can choose to sync an entire SharePoint site, a specific document library, or even individual folders. For this demo, you will select the folder containing the sample financial reports.
- Set metadata, partition, and import mode:
- Metadata: Add metadata like author, department, creation date, and the like, which can be used later to filter search results.
- Partition: Assigning a partition name (eg "finance-reports") to your data helps isolate it from other data sources, allowing you to direct queries to a specific subset of your knowledge base.
- Set a page limit: To manage costs and processing time, you can set a limit on the number of pages to be indexed per document.
- Import mode: You can also choose between hi-res (captures images and tables accurately, thorough extraction) and fast (quicker, lighter extraction) import modes, depending on your needs.
- Audio/video extraction: If your SharePoint contains audio or video files, you can enable audio and video extraction to index these media types as well.
Once you save the connection, Ragie will begin the ingestion process. For more advanced use cases, all of these steps can be automated using the Ragie API.
Building a Node.js App to Query Your Documents
Once your SharePoint documents are indexed, you're ready to build an app that can use them. Let's walk through a simple Node.js CLI app that shows how to retrieve and generate answers from your data.
Project Setup
Create a new directory for your project and install the following dependencies:
- ragie: This is the official Ragie SDK. It provides methods to connect to the Ragie platform, retrieve indexed document chunks, and interact with your knowledge base.
- openai: This is the OpenAI Node.js SDK. It allows you to send prompts and context to OpenAI's language models (like GPT-4) and receive generated responses.
- dotenv: This package loads environment variables from a
.envfile intoprocess.env. It's used to securely manage your API keys and other sensitive configurations without hardcoding them in your source code.
mkdir sharepoint-rag-app && cd sharepoint-rag-app
npm init -y
npm install ragie openai dotenv
Create a .env file to store your API keys:
RAGIE_API_KEY="your_ragie_api_key"
OPENAI_API_KEY="your_openai_api_key"
Retrieve Relevant Chunks
Create a file named index.mjs in your project directory and add the following code to retrieve information from your indexed documents.
import { Ragie } from "ragie";
import OpenAI from "openai";
import dotenv from "dotenv";
import readline from "readline";
dotenv.config();
// Initialize clients with API keys
const ragie = new Ragie({ auth: process.env.RAGIE_API_KEY});
const openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
// Create readline interface for user input
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout
});
// Function to get user query
function getUserQuery() {
return new Promise((resolve) => {
rl.question('Enter your query: ', (answer) => {
resolve(answer);
});
});
}
// Get query from user
const userQuery = await getUserQuery();
rl.close();
if (!userQuery.trim()) {
console.log("No query provided. Exiting.");
process.exit(0);
}
console.log(`\nSearching for: "${userQuery}"\n`);
// 1. Retrieve relevant chunks from Ragie
const response = await ragie.retrievals.retrieve({
query: userQuery,
partition: "financial-reports",
// filter: {
// // optionally filter by metadata
// source: { $eq: "sharepoint" }
// }
});
const chunks = response.scoredChunks;
console.log(`Retrieved ${chunks.length} chunks from Ragie.`);
for (const chunk of chunks) {
console.log("- Chunk snippet:", chunk.text.substring(0, 100), "...");
}
if (chunks.length === 0) {
console.log("No relevant content found for the query.");
process.exit(0);
}
This code uses the Node.js readline module to interactively prompt the user for a query in the terminal. Once the user enters their question, the Ragie client sends it to the retrieval API, which searches your indexed SharePoint documents and partition, and returns the most relevant text chunks for further processing.
Generate a Response
You can now use the retrieved chunks as context to help an LLM answer questions better. Adding context to your prompt helps ensure the model's response is grounded in your specific documents. Add the following code to index.mjs:
// Prepare a system message with instructions and context
const chunkTexts = chunks.map(c => c.text).join("\n\n");
const systemMessage = `
You are an AI assistant using the organization's knowledge base to answer questions. Use ONLY the information provided in the context below to formulate your response.
Guidelines for your responses:
- If you are unsure or the answer is not clearly supported by the context, explicitly state "I don't know" or "This information is not available in the provided documents"
- Always cite specific documents, sections, or sources when referencing information from the context
- When possible, include document titles, page numbers, or other identifying information in your citations
- Structure your answer clearly, separating your main response from your source citations
- If multiple documents contain relevant information, synthesize the information while maintaining clear attribution to each source
- Avoid speculation or inference beyond what is directly stated in the provided context
- If the context contains conflicting information, acknowledge the discrepancy and cite both sources
Context:
${chunkTexts}
`;
// Call OpenAI Chat Completion API (GPT-4 model) with the system message and user query
try {
const chatCompletion = await openai.chat.completions.create({
model: "gpt-4o-mini",
messages: [
{ role: "system", content: systemMessage },
{ role: "user", content: userQuery }
]
});
const answer = chatCompletion.choices[0].message.content;
console.log("\n**Answer:**\n", answer);
} catch (err) {
console.error("Failed to get completion from OpenAI:", err);
}
By passing the chunkTexts in a system prompt, you instruct the LLM to base its answer solely on the information retrieved from your SharePoint documents. The system message includes clear behavioral guidelines for the model: It tells the LLM not to speculate, to cite specific sources when possible, to acknowledge any ambiguity or conflicting information in the context, and to separate the main response from citations. This structured prompt design is crucial for grounding the model's output in your enterprise data and minimizing hallucinations, and it improves the accuracy of the response.
After you set up the system message, the code sends this prompt and the user's query to the OpenAI API, which responds with an intelligent answer that reflects the supplied context.
Test the Application
Run the application from your terminal:
node index.mjs
The application will prompt you to enter a query. For example, you might ask, "What were the top earners in 2024?" or "What are NVIDIA's key AI initiatives?"
Here's what happens when you run the application:
- Query input: The application prompts you to enter your question.
- Document search: Ragie searches through your indexed SharePoint documents to find relevant chunks.
- Context retrieval: The system displays how many relevant chunks were found and shows snippets of the retrieved content.
- Answer generation: OpenAI uses the retrieved context to generate a comprehensive, grounded response.
You should see a similar output to the one below:
Searching for: "What were the top earners in 2024?"
Retrieved 8 chunks from Ragie.
- Chunk snippet: NVDA-F4Q24-Quarterly-Presentation-FINAL.pdf
26,500 21,500 16,500 11,500 6,500 1,500 $6,051 66.1% Q4 ...
...
**Answer:**
In 2024, NVIDIA reported the following revenue figures from their top-earning segments:
1. **Data Center**: Revenue reached $18.40 billion, which represents a year-over-year growth of 409%.
2. **Gaming**: Revenue was $2.87 billion, showing a growth of 56% year-over-year.
Overall, NVIDIA's total revenue for Q4 FY24 was reported at $22.10 billion, reflecting a significant increase of 265% compared to the previous year (Q4 FY23) (Source: NVDA-F4Q24-Quarterly-Presentation-FINAL.pdf).
You can find the full source code for this tutorial on GitHub.
Best Practices
As you move from prototyping to deploying RAG solutions in real enterprise environments, it's important to follow proven operational practices that help ensure reliability, security, and maintainability. Here are a few best practices to keep in mind:
- Use service accounts: For connecting Ragie to SharePoint, use a dedicated service account with permissions scoped to the principle of least privilege.
- Organize documents: Organize your documents in folders or libraries. This makes it easier to manage targeted data partitions within Ragie.
- Monitor syncs: Regularly check the status of your data connections in the Ragie dashboard to ensure your knowledge base remains up-to-date.
Conclusion
You have successfully built a RAG system that connects directly to a SharePoint document library. This allows you to build sophisticated, context-aware AI applications on top of proprietary organizational knowledge.
By leveraging a managed platform for RAG, you can bypass the significant engineering effort required to build and maintain a custom ingestion pipeline. This allows your team to focus on building intelligent applications that deliver business value.
To explore more, check out the full list of Ragie connectors and sign up for a free account to start building today.