Powering Your RAG: Integrating Google Drive for Seamless Knowledge Ingestion


Retrieval-augmented generation (RAG) is an approach that combines a large language model (LLM) with external knowledge bases to enhance its output. LLMs require a vast volume of data and computing resources for training, making it expensive to retrain the model and incorporate new data. RAG addresses this by augmenting models with domain-specific knowledge without retraining the entire model from scratch. This enables LLM models to retrieve and use contextually relevant information before generating a response.
With scale, manually uploading documents to the RAG knowledge base becomes challenging as it's time-consuming and prone to human errors. For LLMs to ingest a large number of documents, businesses often prefer an automated approach where the knowledge base periodically syncs with their file storage systems, such as Google Drive, OneDrive, or SharePoint. This ensures that the LLM relies on a single source of truth and has access to updated documents without human intervention. Ragie is a fast, easy-to-use, accurate, and fully managed multimodal RAG-as-a-service platform for developers. It offers built-in connectors for several data sources, including Confluence, Google Drive, Notion, Salesforce, and OneDrive, allowing businesses to connect and manage their data.
In this tutorial, you'll learn how to connect and ingest documents directly from your Google Drive into your RAG system using the Ragie platform.
Understanding Retrieval-Augmented Generation
Traditional LLMs rely only on the data they were trained on, often resulting in inaccurate or outdated information. RAG enhances the LLM knowledge base with real-time access to external data, allowing AI models to return accurate and contextually relevant responses. The key components of a RAG system include a knowledge base, a retriever, and a generator, as discussed below:
- Retriever: uses vector similarity search to match and return relevant documents from the external data sources based on the user query
- Knowledge base: is an external knowledge base, such as documents, web pages, and audio, video, or PDF files stored in a database or a vector store
- Generator: takes the retrieved context and passes it to an LLM to generate contextually relevant responses
RAG avoids the need to retrain the model from scratch, allowing developers to control LLM responses in a transparent, scalable, and cost-effective manner.
Ragie: Fully Managed Multimodal RAG-as-a-Service
Ragie is a fast, easy-to-use, accurate, and fully managed multimodal RAG-as-a-service platform for developers. It offers developer-friendly APIs and SDKs that allow seamless ingestion of text, audio, video, or PDF files. The SDKs offer advanced features like indexing, chunk reranking, vector filtering, and hybrid semantic and keyword search. These capabilities enable developers to build AI-powered applications for different use cases, including internal tooling, customer support (CS) platforms, and enterprise search.
Ragie offers fully managed connectors for several popular external data sources, such as Google Drive, Confluence, Salesforce, and OneDrive. It handles the authentication and authorization with the data source, allowing secure access to customer data. In this tutorial, you will learn how to connect Google Drive with Ragie and build a RAG application that queries documents synced through it.
Prerequisites
Before you get started, you will need to:
- install the Node.js development environment;
- sign up for a Ragie account;
- install Ragie CLI on your development machine; and
- generate a Ragie API key.
Set Up the Starter Project
This tutorial uses this starter code containing a sample data file for ingestion. To follow along, clone the GitHub repo and switch to the starter branch:
git clone https://github.com/maskaravivek/ragie-google-drive-example.git
cd ragie-google-drive-example
git checkout starter
The starter code contains the following:
- The file
package.json, with OpenAI and Ragie npm dependencies installed - The
index.mjsscript, containing logic to parse the command line arguments - The
datadirectory, containing a few text files that you can use in later sections for ingesting data into Ragie
Before you get started, execute the following command on your machine to configure it as an environment variable:
export RAGIE_API_KEY=<YOUR_RAGIE_API_KEY>
The above command will configure the API key in your terminal environment. Note that you will need to rerun the command if you restart the terminal session.
Connect and Ingest Documents from Google Drive
Before connecting Google Drive with Ragie, create a new folder in your Google Drive and add some files that you want to ingest. You can upload either text, audio, video, or PDF files as per your application's requirements. For this tutorial, upload the files under the data directory of the GitHub project to Google Drive.

To connect Google Drive, navigate to the Connections page on the Ragie developer portal and select New Connection > Google Drive to initiate the connection.
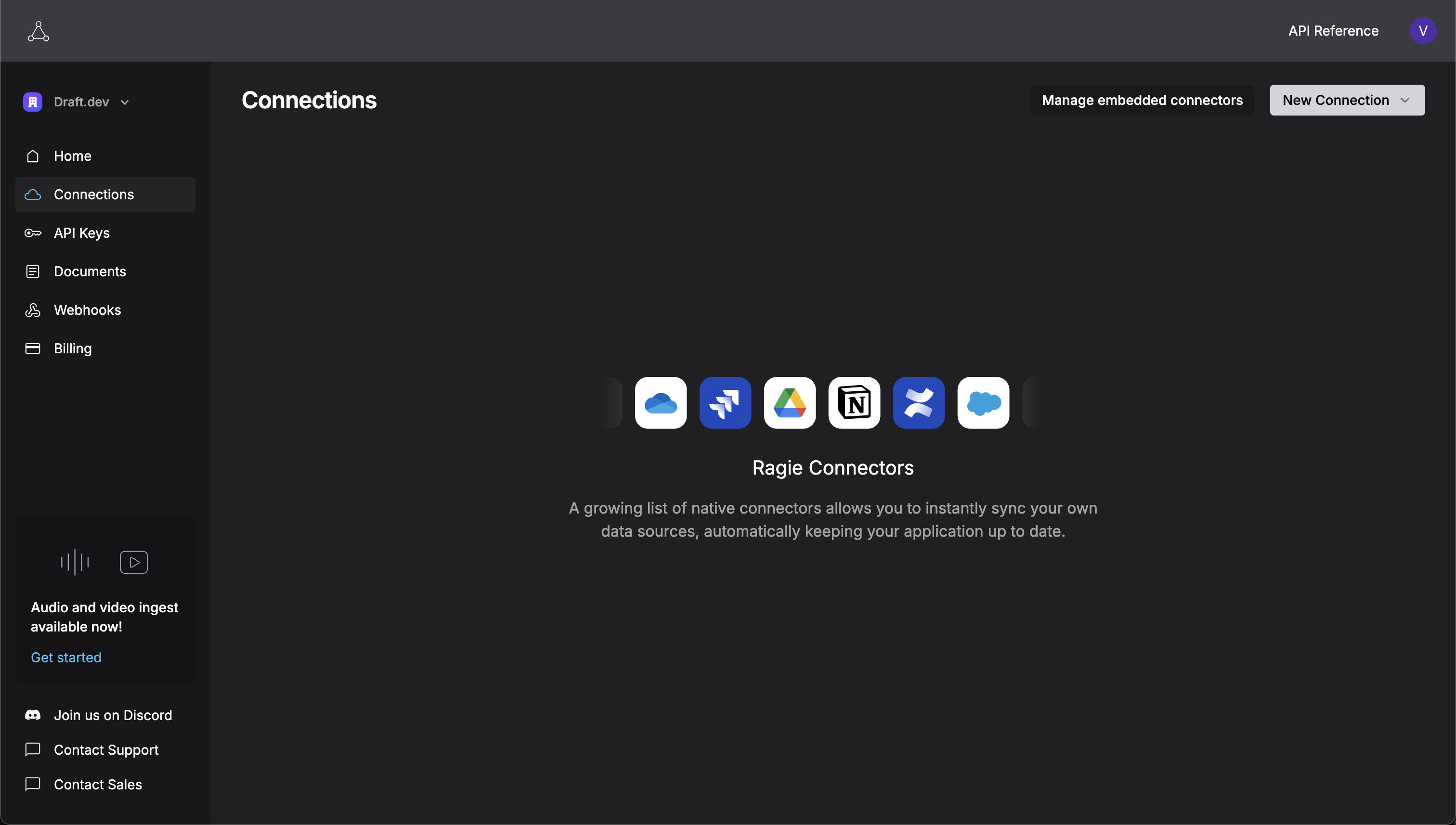
Ragie will redirect you to the Google authentication page, where you can authenticate the connection and grant the required permissions to establish the connection.

After authentication, Ragie will prompt you to configure the connection properties, where you can choose the folder you want to sync and the partition to be used. Click the Files picker to choose the Google Drive folder that you want to sync with Ragie.

Ragie allows documents to be logically separated into partitions, and retrievals can be performed based on an optional partition parameter, which, when present, scopes the retrieval to documents in the given partition. Set a unique name for the partition—for example google-drive-partition.

Click the Create connection button to complete the connection setup. Once the connection is created, the page will display the connection as Syncing, indicating that documents are being ingested into Ragie.

Navigate to the Ragie Documents page, which should show all the documents in the RAG folder syncing with Ragie.

Now that your connection is set up, anytime you add a new file to the RAG folder on Google Drive, it will sync it with Ragie.
Perform Retrievals Using a Node.js Application
Now that you have connected Google Drive with Ragie, you can create an application to retrieve raw chunks and generate LLM responses. The starter code includes an npm project initialized with the index.mjs script, which can parse command line arguments. In this section, you will learn how to extend the application to add functions that can retrieve documents and generate responses using OpenAI.
Retrieve Chunks
You can use the Retrieval API to fetch document chunks from Ragie. Add the following code snippet to the index.mjs file to retrieve chunks based on the input query:
async function retrieveChunks({ query }) {
if (!query) {
console.error("Error: --query is required for retrieve-chunks operation.");
process.exit(1);
}
const response = await ragie.retrievals.retrieve({
partition: "google-drive-partition",
query
});
return response;
}
(async () => {
if (operation === "retrieve-chunks") {
// invoke the retrieveChunks method here
const response = await retrieveChunks(params);
console.log(response);
}
...
// existing code
})();
The retrieveChunks method reads the query parameter from the CLI and outputs the retrieved document chunks. Execute the following command to use this method with a sample text from the ingested document:
node index.mjs retrieve-chunks --query="rescan about 30 images of men's shirts"
The command returns all matching chunks from the document, as shown below:
{
scoredChunks: [
{
text: 'paul_graham_essay_drive.txt\n' +
"There were a lot of startups making ecommerce software in the second half of the 90s. We were determined to be the Microsoft Word, not the Interleaf. Which meant being easy to use and inexpensive. ---OUTPUT_TRIMMED--- to rescan about 30 images of men's shirts. My first set of scans were so beautiful too.",
score: 0.2,
id: 'fbf425dc-5992-41a8-894c-29c6c44c890f',
index: 32,
metadata: {},
documentId: 'ead9e86c-efa3-49dd-97f0-32c7901fc564',
documentName: 'paul_graham_essay_drive.txt',
documentMetadata: [Object],
links: [Object]
},
...
]
}
Notice that the retrieved chunks contain the matching text provided in the query. You can filter chunks by metadata to extract better results and use the retrieved chunks to generate an LLM response.
Generate LLM Response
You can pass the retrieved raw chunks to the LLM to generate a contextually relevant response. The retrieved chunks provide the LLM with additional context about the query, helping improve its response without retraining the entire model. Add the following code snippet to the index.mjs file to generate responses based on the input query:
async function retrieveChunks({ query }) {
// existing code
}
async function generate({ query }) {
const openAiApiKey = process.env.OPENAI_API_KEY;
if (!openAiApiKey) {
console.error("Error: OPENAI_API_KEY environment variable not set.");
process.exit(1);
}
if (!query) {
console.error("Error: --query is required for generate operation.");
process.exit(1);
}
try {
const response = await retrieveChunks({ query });
const chunkText = (response.scoredChunks || response.scored_chunks || []).map((chunk) => chunk.text);
const systemPrompt = `These are very important to follow:
You are "Ragie AI", a professional but friendly AI chatbot working as an assistant to the user.
Your current task is to help the user based on all of the information available to you shown below.
Answer informally, directly, and concisely without a heading or greeting, but include everything relevant.
Use richtext Markdown when appropriate including **bold**, *italic*, paragraphs, and lists when helpful.
If using LaTeX, use double $$ as delimiter instead of single $. Use $$...$$ instead of parentheses.
Organize information into multiple sections or points when appropriate.
Don't include raw item IDs or other raw fields from the source.
Don't use XML or other markup unless requested by the user.
Here is all of the information available to answer the user:
===
${chunkText}
===
If the user asked for a search and there are no results, make sure to let the user know that you couldn't find anything,
and what they might be able to do to find the information they need.
END SYSTEM INSTRUCTIONS`;
const openai = new OpenAI({ apiKey: openAiApiKey });
try {
const chatCompletion = await openai.chat.completions.create({
messages: [
{ role: "system", content: systemPrompt },
{ role: "user", content: query },
],
model: "gpt-4o",
});
return chatCompletion.choices[0].message.content;
} catch (error) {
console.error("Failed to get completion from OpenAI:", error);
process.exit(1);
}
} catch (error) {
console.error("Failed to retrieve data from Ragie API:", error);
process.exit(1);
}
}
(async () => {
if (... // existing conditions) {
...
// existing code
} else if (operation === "generate") {
const response = await generate(params);
console.log(response);
}
...
// existing code
})();
Let's go over the code snippet to understand how a response is generated:
- The
generatemethod reads thequeryfrom the CLI and invokesretrieveChunksto get the matching chunks. Since theretrieveChunksmethod uses thegoogle-drive-partitionpartition, only documents from Google Drive will be retrieved from the Ragie knowledge base. - A
systemPromptis constructed, containing the system instructions and the extracted text from the retriever. The raw chunks help LLMs generate content for data that they have not been trained on. - Finally, an
openai.chat.completions.createAPI call to OpenAI is made to generate a meaningful response to the user query. The tutorial uses the GPT-4o LLM model, but you can swap it out for a different model based on your use case.
Refer to the Ragie docs to learn more about the generation process. You can use this script by executing the following command with a user query:
node index.mjs generate --query="What is Paul telling us about Piazza San Marco"
The command returns the LLM response as shown below:
Paul Graham mentions Piazza San Marco as part of his daily walk route while living in Florence. He describes his journey to the Accademia, which takes him through notable landmarks in Florence, eventually leading up Via Ricasoli to Piazza San Marco. Through this, he provides a vivid sense of experiencing Florence at street level in various conditions, from quiet winter evenings to bustling summer days crowded with tourists.
The response demonstrates that the LLM is aware of the contents of the ingested document even though it wasn't initially trained on it.
Conclusion
In this tutorial, you learned how to connect Google Drive with Ragie to ingest documents automatically. You also learned how you can easily retrieve chunks and generate LLM responses using the Ragie Node.js SDK and get started with RAG within minutes. You can find the complete source code for this tutorial on GitHub.
Sign up for Ragie, and check out available connectors supported by Ragie.