The Architect's Guide to Production RAG: Navigating Challenges and Building Scalable AI


Retrieval-augmented generation (RAG) is a method that improves large language models (LLMs) by retrieving external knowledge during the generation of the response. RAG combines the strengths of LLMs with external knowledge retrieval to enhance their capabilities. With RAG, an LLM is not limited to its fixed training data. Instead, the LLM retrieves information from external knowledge bases using hybrid search methods, combining both vector and keyword-based searches to provide accurate and contextually relevant responses. The LLM then utilizes the retrieved information to generate an answer, which allows it to provide more precise, up-to-date, and domain-specific answers without the need to retrain the model. Open source frameworks and SDKs enable the rapid prototyping of RAG pipelines. They provide plug-and-play components for data ingestion, retrieval, and generation. This allows the user to create a proof of concept for a RAG pipeline, typically within a few hours.
However, implementing this prototype into a production-ready system has many hurdles. In practice, RAG systems must balance inference latency, API costs, data freshness and consistency, retrieval accuracy, and security.
This guide explores the structure of RAG systems, the associated technical challenges, and the best practices and tools needed to split, retrieve, optimize, and evaluate these pipelines for reliability and scalability.
Overview of the Architecture: Knowledge Base, Retriever, and Generator
A typical RAG architecture consists of three main components:
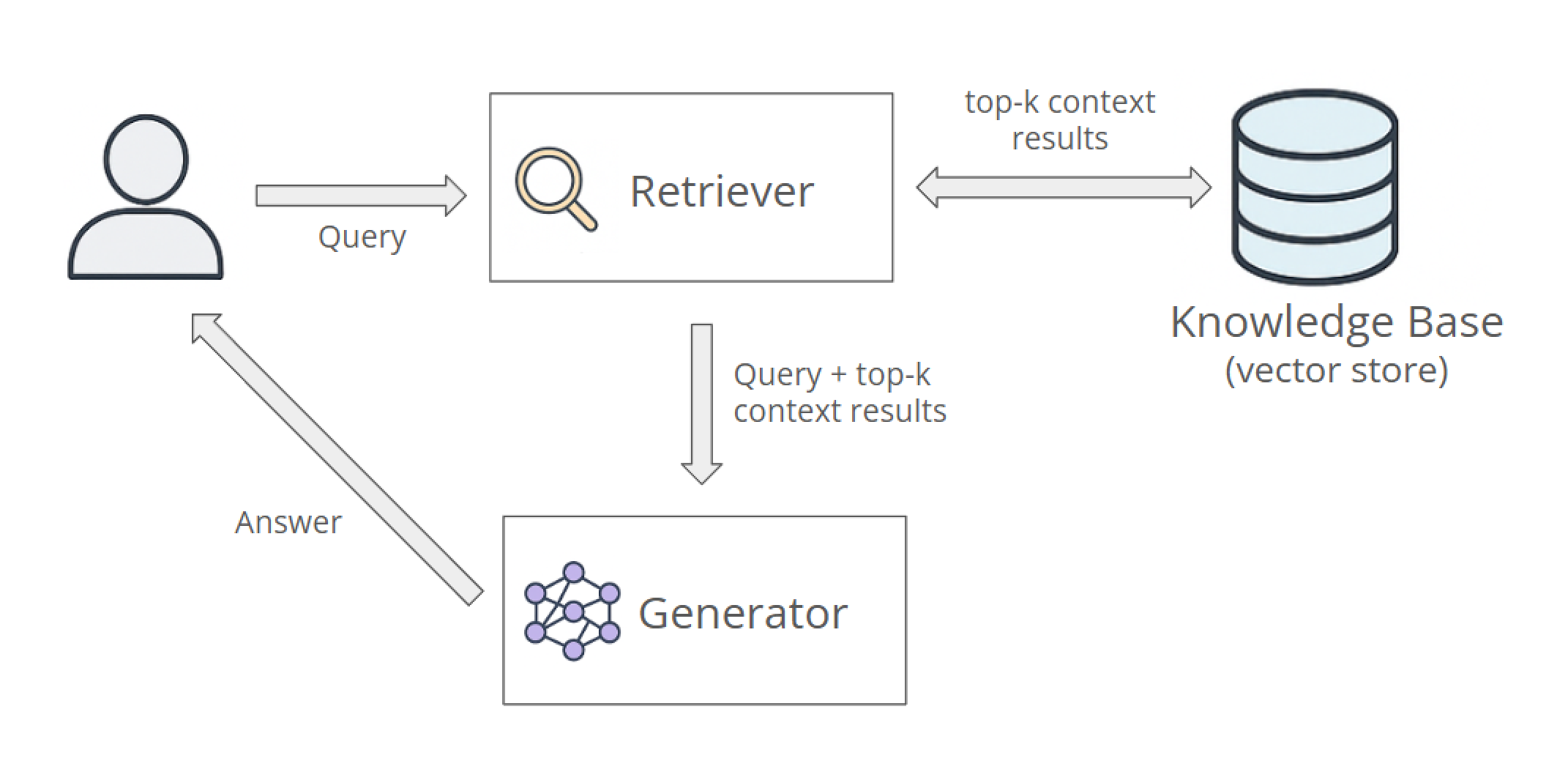
- Knowledge base: The knowledge base stores indexed information, usually in specialized databases such as vector databases or hybrid stores, enabling quick retrieval of relevant documents based on semantic similarity.
- Retriever: When a user submits a query, the retriever finds relevant document fragments (context) from the knowledge base. It typically converts the query into embeddings, which are numerical representations that capture semantic meaning. Following that, it then performs similarity searches. Retrieval may involve methods like approximate nearest neighbor (ANN) or hybrid search combining keyword and vector-based strategies. For further details on advanced retrieval methods, refer to Ragie.ai's retrieval engine.
- Generator: After the retriever identifies the most relevant documents, they are merged with the original user's query into a single prompt and passed to the LLM. The prompt for the generator is also supplemented with additional instructions for generating the response. This can include demonstration examples, role-based system messages, or style guidelines that define the tone, format, and depth of the generated response.
Orchestration between the retriever and the generator is important to ensure a production-ready RAG system. Any delays or inaccuracies in retrieving relevant contexts will impact responsiveness, the quality of the answers, and the overall user experience. Effective orchestration includes rapid query processing, managing fallback strategies when immediate matches are unavailable, and continuously monitoring system performance. Inefficiencies in this area often lead to general problems such as retrieval inaccuracies, longer latencies, and higher operational costs, among other challenges, which are discussed in detail in the following section.
Common Challenges in a RAG System
In practice, RAG systems can encounter a number of technical and operational hurdles, including challenges related to data ingestion, retrieval accuracy, and performance overhead.
Data Ingestion Issues
Before documents can be used in a RAG pipeline, they must be extracted, cleaned, and divided into meaningful chunks, which is a process that often suffers from several issues:
- Data extraction from complex sources: In practice, information is distributed across many different sources, such as PDFs, SharePoint sites, relational databases, Jira tickets, or S3 image buckets. Correctly extracting and preprocessing this data can be complex, and many challenges can occur during data extraction. OCR scans can fail at low resolutions, HTML scrapers must handle nested iframes, and spreadsheets require type inference to distinguish currency values from percentages.
- Choosing the optimal chunk size and strategy: After the document text has been extracted, it must be divided into chunks—individual document fragments that will later be embedded and stored in the vector database. The choice of a chunking strategy is very important. If the chunks are too large, they may exceed the context window of the LLM, while chunks that are too small may contain too little relevant information. Blind, fixed-length chunking (eg every 512 tokens) often separates tables from labels or code blocks from comments, creating orphaned fragments that the retriever can later misinterpret.
Data Retrieval Issues
Even with a well-populated vector database, finding the right document chunks can fail due to several issues:
- Missing content: If important files or data types—such as audio, video, or structured documents—have not been added to the vector database, the retriever cannot find them. This can happen when new data sources have not yet been processed or integrated. As a result, the user request may reach the generator without the necessary context, which can increase the likelihood of an incorrect or incomplete response. Solutions like Ragie connectors are designed to process such multimodal data sources more effectively.
- Search inaccuracies: Even if the correct document is present, the vector search may retrieve passages that appear similar in the embedding space but do not match the specific search intent. This often happens when domain-specific terminology contaminates the similarity metric. For example, consider a query about "mercury exposure limits." The retriever might return a section about the planet Mercury instead of health and safety guidelines for the metal because the embedding model considers the homonym to be semantically similar.
- Loss of context: Excessive chunking can result in logically related sentences, footnotes, or table headings being separated from their corresponding figures. The retriever may retrieve the heading without the figures or vice versa, omitting important context.
Operational Costs and Performance Issues
At the production scale, RAG systems may struggle to balance end-to-end latency and infrastructure expenditure:
- Response latency: A RAG production pipeline typically integrates multiple data stores rather than relying on a single source. In a single query path, it may simultaneously access a vector database for semantic search, a keyword index for lexical fallbacks, and sometimes a relational database or graph store for structured lookups. Each network round trip can add dozens of milliseconds, increasing overall chat latency. This latency problem is particularly acute on the vector side, where modern embedding models output vectors with 1024–2048 dimensions. Similarity searches across such high-dimensional vectors often result in cache misses and memory bandwidth contention.
- Higher costs: Premium models (eg GPT models and Claude 4 Opus) can cost over $10 USD per million input and output tokens. The vector store may leave an additional financial footprint. Consider that a 1536-dimensional float16 embedding needs approximately 3 KB, including metadata. A text corpus of 500 million chunks will consume approximately 1.5 TB of primary storage.
Strategies for Building Production-Grade RAG
The transition from prototype to production requires proven methods and best practices for data preprocessing, refining data retrieval, and system-level optimization.
Data Chunking and Preprocessing
As mentioned, poorly chunked documents are problematic for RAG. When logical units—such as sentences, list items, and table headings—are arbitrarily split or merged, the retriever either misses the relevant facts or feeds the generator with fragments that no longer make sense. As a result, the LLM begins to hallucinate. Carefully chunked data, on the other hand, ensures that the LLM has everything it needs to provide a reliable answer. Two strategies can help you achieve optimal chunking: hierarchical and semantic chunking.
Hierarchical Chunking
Hierarchical chunking is a top-down approach that tries to reflect the structure of the document. For example, if the text to be chunked is a legal contract, it is first divided into articles, then into sections, and finally into clauses. Each node stores a pointer to its parent node, allowing the retriever to increase or decrease the context granularity as needed. These hierarchies are particularly advantageous when the text corpus itself is highly structured. Examples may include laws, API specifications, and technical manuals. A question about "Article 5, Section 12" benefits from retrieving both the specific sentence and the parent heading.
However, hierarchical chunking requires a trade-off between accuracy and latency. Retrieving a parent sentence and its child sentences can double or triple the token payload. This can result in exceeding the LLM's context window.
Semantic Chunking
During semantic chunking, the document text is split at key discourse boundaries, such as sentence ends, section ends, paragraph breaks, or speaker changes. The goal here is for each chunk to express a single atomic concept. This strategy is useful when the text corpus consists of narrative or free-form content, such as blogs, FAQs, or chat transcripts. For this type of content, semantics are more important than clear headings. This strategy also has trade-offs. While smaller semantic chunks can improve precision, they may require increasing the top-k number, which increases the retriever's search time.
Ragie's advanced chunking approach is optimized for real-world performance that balances precision and efficiency across diverse content types. Benchmark results demonstrate that effective chunking can significantly improve retrieval quality and downstream generation accuracy, as shown in evaluations like LegalBench.
Decomposing Queries
Questions with multiple clauses often pose problems for simple query techniques since each complex question must be represented by a single vector embedding. Query decomposition solves this problem by breaking the user input into separate subqueries, each targeting a specific aspect of the original question. You can achieve this decomposition using either regular expression heuristics or LLM-based parsing. Each subquery receives its own embedding and search in the vector database. An orchestrator then merges the resulting passages. For example, the compound query "Compare the environmental impacts of lithium-ion batteries and solid-state batteries for electric vehicles and explain how each technology affects supply chain costs" would be decomposed into three focused subqueries: two on environmental impacts ("environmental impact of lithium-ion batteries in EVs" and "environmental impact of solid-state batteries in EVs") and one on supply chain costs ("supply chain cost implications of lithium-ion vs. solid-state batteries").
Reranking
While a pure top-k search can quickly deliver matching document chunks, a downstream reranker can further reduce these fragments to truly relevant information. In this case, a cross-encoder evaluates the found top-k chunks paired with the user query and ranks them purely according to semantic relevance. This becomes clear in the search query "What are the health benefits of Apple?" A search in the vector database would, for example, find entries on the vitamin C content of apples as well as press releases on Apple's tax strategy. However, the reranker would understand the context of the question and assign a higher score to document fragments that address the health benefits of apples.
Many production‑grade toolkits, including the Ragie.ai SDK, incorporate reranking out of the box. That spares teams from building this model themselves. The SDK applies an optional reranker to the top blocks so that genuinely relevant content surfaces even when newer data might otherwise crowd it out. Ragie’s retrieval pipeline also supports an optional recency bias feature for time-aware weighting, allowing the retriever to prioritize recent documents and surface fresh content more readily.
Tweaking LLM generation Parameters: Temperature, Top-k/p Sampling
The way an LLM generates text and how predictable, varied, or adventurous each sentence feels is mainly determined by two hyperparameters: temperature and top-p (nucleus sampling). Temperature rescales the model's probability distribution before each token selection. At a temperature of 0, the token with the highest probability is always selected. This makes the generated text highly deterministic and literal. This style is well suited for texts like contracts, policies, and code. A value in the range of 0.6 to 0.8 causes the distribution to flatten, which gives the less likely tokens a chance to appear. This makes the output more creative. At a temperature close to or above 1.0, the LLM becomes increasingly unpredictable and may hallucinate or generate incoherent or overly random text.
Top-p, on the other hand, affects randomness from a different perspective. Instead of scanning the entire vocabulary, the model limits its selection to the smallest set of tokens whose cumulative probability mass reaches the threshold p. With a value of p = 0.8, the LLM focuses on the generation of the most likely words and increases coherence. At p = 1.0, however, this safety net is removed. The model is now allowed to access the entire distribution.
In production systems, the two parameters are typically set in parallel. Strict texts, such as legal notices, often combine a temperature between 0 and 0.1 with a p-value of 1.0. Tasks that reward novelty, such as marketing texts or brainstorming prompts, tend to use a temperature around 0.7 and a p-value between 0.85 and 0.9.
Latency Reduction
Production RAG systems can significantly optimize latency through caching, batching, and distributed architecture.
Caching Strategies
Often, a RAG request is a repetition of a previous request from another user. Therefore, the vector search, the prompt, and possibly even the response are identical. Caching allows a response to be repeated without unnecessarily repeating the execution of the entire pipeline. There exist primarily two caching strategies:
- Retriever-level caches: The cache stores previously performed vector searches. If an identical (or semantically very similar) request occurs again, the result of the vector search is returned directly—without reaccessing the vector index. This saves search time and reduces IO load.
- Prompt-level caches: The user question can be hashed along with the retrieved context (eg using SHA256). If the same hash is already present in the cache, the cached LLM response can be returned immediately without having to be passed back to the LLM. This strategy is particularly effective for common standard queries or FAQs.
Query Batching
LLM computations on GPUs are inherently parallel. A single forward pass multiplies large matrices simultaneously across thousands of cores. Batching multiple prompts allows the GPU to be fully utilized, ensuring no core is idle because the system executes them in the same pass. Processing a batch of, say, eight prompts may take slightly longer than processing a single one; however, the average latency per request decreases because all eight prompts are now processed in a single pass. This means users receive faster responses, and the service can handle more traffic without additional hardware.
Distributed Architecture
While batching can increase the throughput of a single GPU, in practice, production traffic can eventually exceed the capacity of a single machine. This problem can be addressed with a distributed setup by scaling between machines in two complementary ways.
The first is horizontal fragmentation of the embedding index, where the text corpus is divided into multiple Hierarchical navigable small world (HNSW) indexes located on separate nodes. A query is forwarded to each shard, and the system merges the top-k hits. With this approach, search capacity scales almost linearly with the number of shards and is therefore widely used in RAG systems.
The second approach involves distributing the pipeline services, such as retriever, optional reranker, and generator, which can be orchestrated asynchronously using a queue like Kafka or Redis Streams. Each component operates at its own pace and submits results through the queue. This absorbs traffic spikes and prevents a slow phase from blocking the rest.
Ragie's cloud APIs are designed for this type of horizontal scaling. Using the retrieval endpoint documented in the API quickstart, multiple stateless workers can be set up behind a load balancer, allowing capacity to grow by simply adding instances.
Evaluating RAG Quality in the Production Environment
Once a RAG pipeline has been implemented and scaled to production traffic, continuous quality monitoring is the next logical priority. An evaluation framework should combine automated metrics with targeted human review to monitor both retrieval accuracy and generation clarity. It ensures a smooth transition of a RAG system from proof of concept to production.
Quality assessment can combine automated and user-centered metrics. For example, retrieval precision and recall can be used to measure the effectiveness of the system's selection of relevant passages, while metrics such as ROUGE-L or BERTScore compare generated content with high-quality references. Furthermore, human-in-the-loop ratings based on Likert scales for assessing relevance and understandability can provide important context when automated ratings are insufficient. For example, in a summarization pipeline, system-generated ROUGE-L summaries can be reviewed against a reference corpus and subsequently reviewed for coherence by human reviewers. This demonstrates that a high ROUGE score does not always correlate with understandability in real-world use.
Designing for Scalability
Once the quality control of a RAG system is established, the focus shifts to longevity. This includes handling growing data traffic without cost spikes or latency and without compromising security and privacy aspects.
Cost and Performance Optimization
As demand in the RAG pipeline increases, so do costs and latency. However, this can be counteracted with a few levers that usually deliver rapid and noticeable improvements:
- Choosing the right vector database: Optimizing cost and performance in a RAG pipeline begins with selecting the most suitable vector database and model architecture for the specific workload. For example, Qdrant and Faiss offer open source vector storage alternatives compared to premium-priced commercial solutions.
- Leverage approximate nearest-neighbor indexes: Furthermore, using approximate nearest-neighbor indexes like HNSW or IVFPQ can drastically reduce query latency with minimal impact on accuracy.
- Optimize embedding and generation models: Optimizing embedding and generation models using techniques like weight quantization and pruning is also important. The model size is the second lever. Modern LLMs with billions of parameters increase both the time to generate an answer and the memory requirements. One option here is to switch to quantized variants of LLMs, which are often 30–60 percent smaller and exhibit little loss of quality.
Managing Security and Privacy for Scaled Applications
Scaling a RAG pipeline increases throughput and, thus, the potential impact of data or privacy breaches. To ensure user trust and compliance, security measures must be integrated at every step. Mature RAG stacks must encrypt embeddings at rest, enforce TLS in transit, and tag each block with row-based access tags before it reaches the index. These security considerations also apply to inference. Prompts and context must be routed through dedicated queues to prevent cross-client data loss. Sensitive fields in the prompt—such as emails, phone numbers, personally identifiable information, and the like—must be automatically detected, redacted, or hashed before embedding. These measures ensure that a lost vector index cannot be reverse-engineered back into raw secrets. Additionally, audit logs must be maintained to log every fetch and generated call, ensuring compliance.
Conclusion
In this guide, we explored how the RAG architecture is based on the triad of knowledge base, retriever, and generator. Each of these three factors plays an important role in delivering accurate and context-relevant answers. We also examined operational challenges—from chunking strategies and retrieval accuracy to latency and cost—as well as best practices for optimizing and scaling a RAG pipeline to production readiness.
Ultimately, the success of a RAG system depends on thoughtful design and architectural decisions. A well-designed system accurately retrieves only relevant context and also ensures low-latency, cost-effective, and secure result delivery. Fine-tuning components such as chunking logic, reranking models, and orchestration layers is critical for high performance and user confidence.
While building a sophisticated RAG system from scratch offers deep customization, it demands considerable expertise and resources. For teams looking to accelerate development, ensure best practices are baked in, and focus on their core application logic, a managed RAG-as-a-service platform like Ragie can provide a powerful, streamlined alternative, handling the underlying complexities for you.